
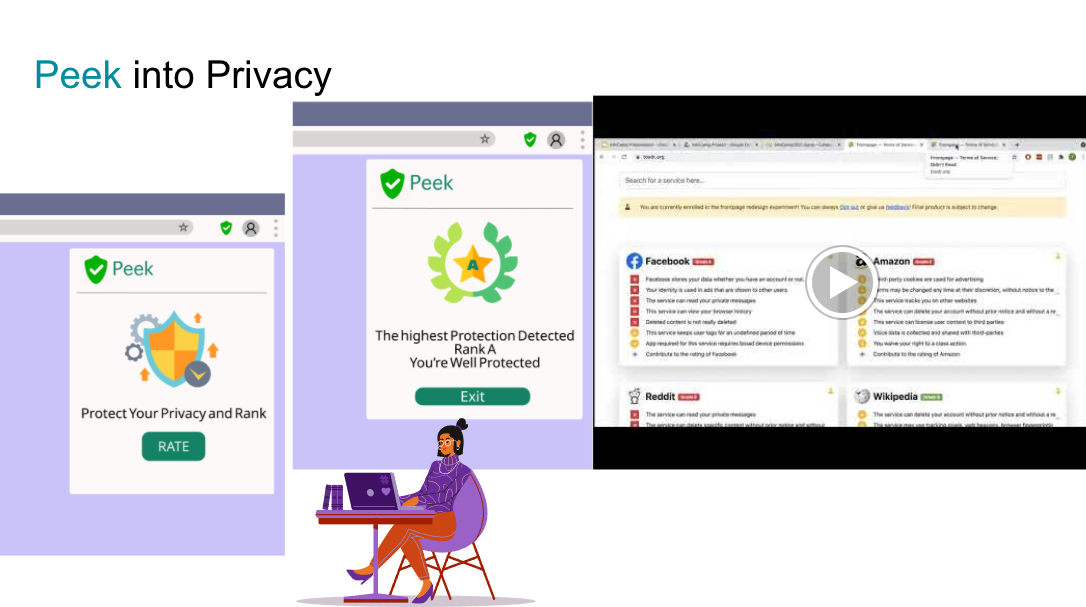
The real-world challenge tackled in the Idea-thon is to find solutions that make the privacy agreement more accessible and legible for the public. Working with Tal Segal, we created Peek, a rating system for privacy policy agreement with machine learning, as our deliverable for the Idea-thon, by applying problem-solving, communication, and teamwork skills.
Professor Deirdre Mulligan inspired me to study the design of systems and the ethical consideration behind the algorithms. Collaboratively designed and executed the concept in a dense timeframe, I learned to think outside the box, understand the problem from user and creator perspectives, and apply classroom knowledge to a real-world challenge. The future implications of this project can protect individuals’ privacy against large data firms by diluting the terms of service statements in a comprehensible manner. It ensures users understand the cost and benefit of using a service and prevent potential injuries caused by misuse of personal data due to lack of understanding.

What is the Problem?
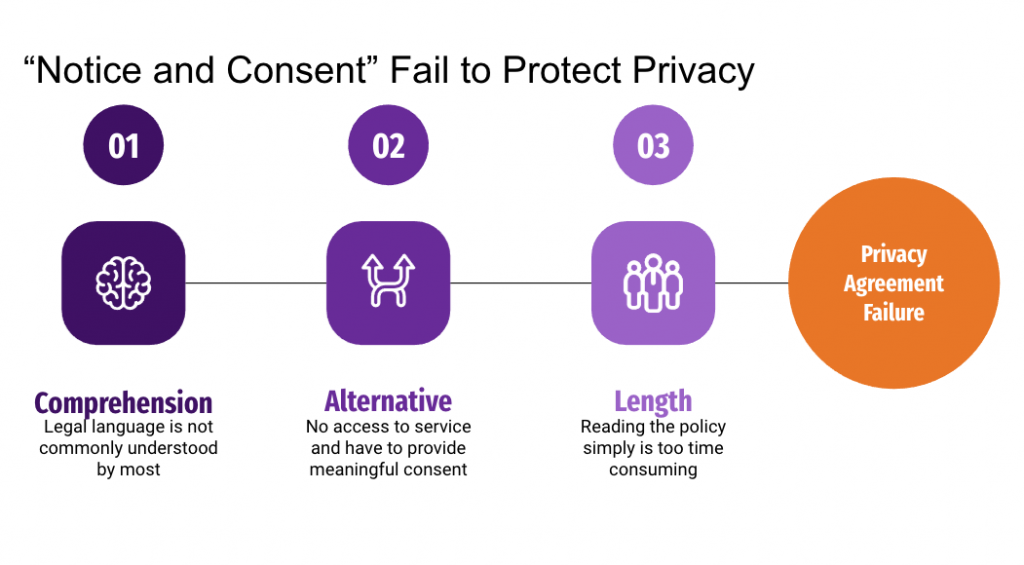
Privacy is the control over personal information/ data. Currently, most of the “Notice and Consent” forms fail to protect our privacy. It is hard to comprehend for the public without a legal background. Most of the time, there is no alternative for a limited service. Without consent, one has no access to the service they seek. This design of the consent policy fails to allow one to grant meaningful permission. Nevertheless, the privacy agreement is too lengthy and simply too time-consuming to read. These problems exist for adults, but it is even more critical for children and elders who tend to have less knowledge of the subject and are more vulnerable to a breach of privacy security.
What is the current solution?
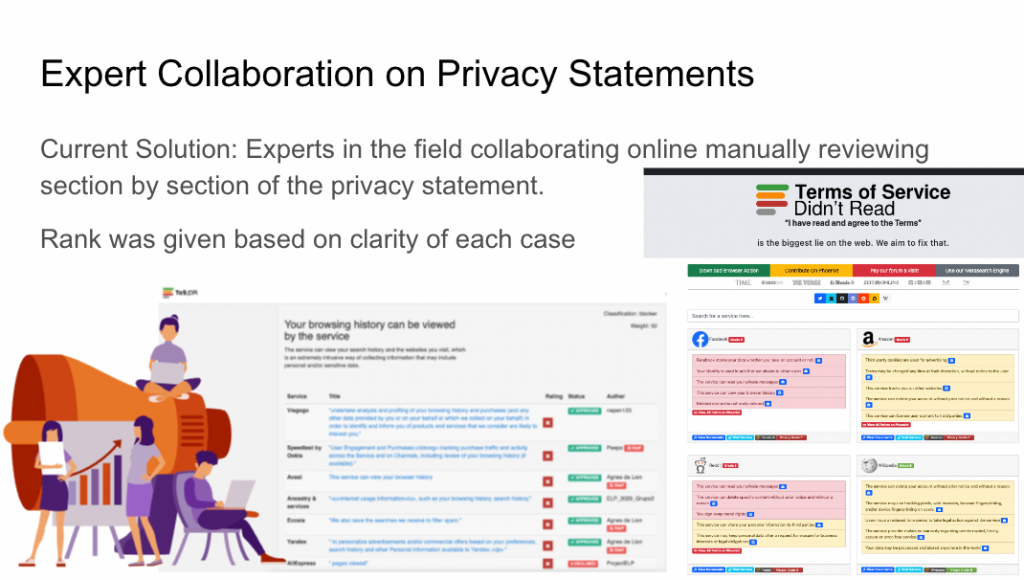
Tal and I found an open-source organization, “Terms of Services Don’t Read” (ToSDR), where they aim to collaborate with experts online to review the privacy agreements of various online services manually. Breaking down into cases, they review and verify each service provider under each condition. An example of a case is whether the service views your browser history. After compiling all the instances, a rank is given to the service provider where rank A is the most protect and rank E is less protected.
This is our approach:
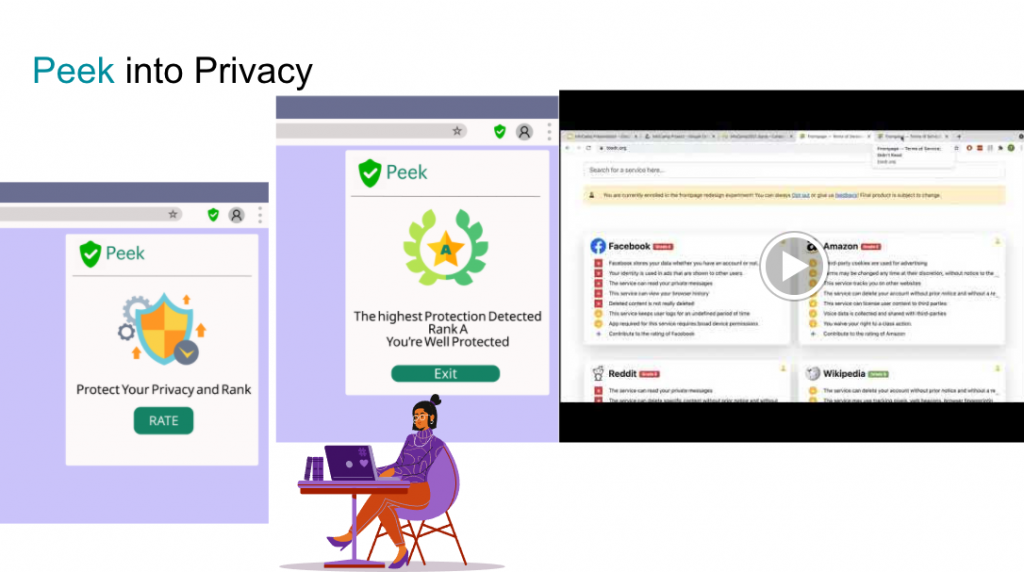
Building on top of ToSDR, Tal and I created “Peek” using a machine learning algorithm to train and predict the rank of services providers that ToSDR does not yet rank. The primary target users of Peek are children who are now growing up in the technology environment and may not understand the importance of protecting personal information. Peek assists children and their parents in getting the most basic sense of how protected you are by the agreement on an A to E scale. When a service receives a low rank, more investigation from a human agent (parents) is suggested. Peek improves the accessibility, legibility, and effectiveness of the privacy policy for youth and provides a baseline understanding of the level of personal information shared with the service providers.

Let’s Peek into privacy:
In the future, Peek can be deployed as a browser extension. It will use the web scraping technique to gain the privacy policy information of the site. By clicking the browser extension, Peek, to activate. In real-time, a privacy rating of the service user is on is provided. A coding demo is also available here. I created a visual demo of the user interface of Peek using Figma.
Discussion
Machine learning algorithms perform tasks without explicit instructions, and rely heavily on patterns. By design, the result of Peek is heavily dependent on the user-generated ranking content. Peek is a big vision idea that serves as a prototype showing the possibility of using machine learning to provide privacy ratings of web services. It is crucial to remember that Peek is designed to be used as sufficient justification, not causation. It doesn’t reflect whether individuals should consent to service but give a baseline assessment on the privacy protection of that service.
InfoCamp is a 2-day (Oct 16-17, 2021) event held by UC Berkeley, School of Information, featuring an Idea-thon and speaker series. This year’s theme is “Our Data/ Our Selves” to draw attention to the ownership and distribution of data as AI and machine learning technologies can be applied to causes that bring controversies.

